Ridley UID: 1327522
精华: 0
发帖: 243
HP: 0 点
SP币: 13013 G
昵称: Ridley
在线时间: 1371(小时)
注册时间: 2020-08-11
最后登录: 2024-05-16 | [comfyui] 一键AI去衣工作流教程(二)—— 自动识别
本教程系列最终为了在comfyui里实现“一键AI去衣”工作流,参考https://bbs.imoutolove.me/read.php?tid-2157478.html。
在阅读本帖前请务必先阅读基础篇教程:https://bbs.imoutolove.me/read.php?tid-2160293.html。
本篇教程为第二篇——自动识别,主要介绍如何在comfyui中自动识别人体部位,以提高绘制蒙版的质量或者直接免去手绘蒙版。通常情况下基础篇工作流已经足够使用了,之后的教程更多的是进阶用法。
第三篇——肤色与修复(完结):https://bbs.imoutolove.me/read.php?tid-2173721.html
正式版工作流:https://bbs.imoutolove.me/read.php?tid-2180363.html
问题回答
一些问题可能在接下来的教程里会得到解答,但在这里先统一回复一遍
1. 为什么我“去衣”后的肤色跟原肤色差异非常大?
答:(1) 你的重绘蒙版跟提示词不符。比如你的蒙版区域只有局部人体,但在写提示词时使用了nude或者completely_nude,模型在采样时有几率会将肤色与衣着颜色混淆。解决方法:蒙版涂抹更全面 或 用更准确的提示词描述;
(2) 你选用的大模型和vae跟图像不契合。解决方法:选用能画出跟图像人物肤色相近颜色的大模型与vae 或 添加肤色lora;
(3) 你的{遮罩混合颜色}选取的RGB颜色跟肤色差异过大;
2. 为什么我重绘后的姿态或构图跟原图差距过大?
答:姿势相对复杂。
解决方法:(a) 完善提示词,加入姿势与构图的提示词 ;
(b) 使用额外的controlnet模型,比如depth, normalbae, 但降低权重和结束时间,直到达到去衣和构图的平衡点;
3. 我第一次接触Stable Diffusion,直接用comfyui可以么?
答:如果你对AI画图的原理感兴趣并且有足够的时间精力,可以跳过A1111的webui直接使用comfyui;如果你只是对AI画图最后的成果图感兴趣,建议先用A1111的webui入门和培养兴趣,并多接触各类模型与插件;
如果你的显存小于6G,那么恭喜你,你在本地运行基本只能靠comfyui或forge(forge目前缺少插件支持);
自动识别工作流
本工作流建立在基础篇工作流的基础之上,请确保你已经理解基础篇工作流。在测试局部工作流时,可以先将其他工作流节点和组右键忽略。
1. 自动遮罩
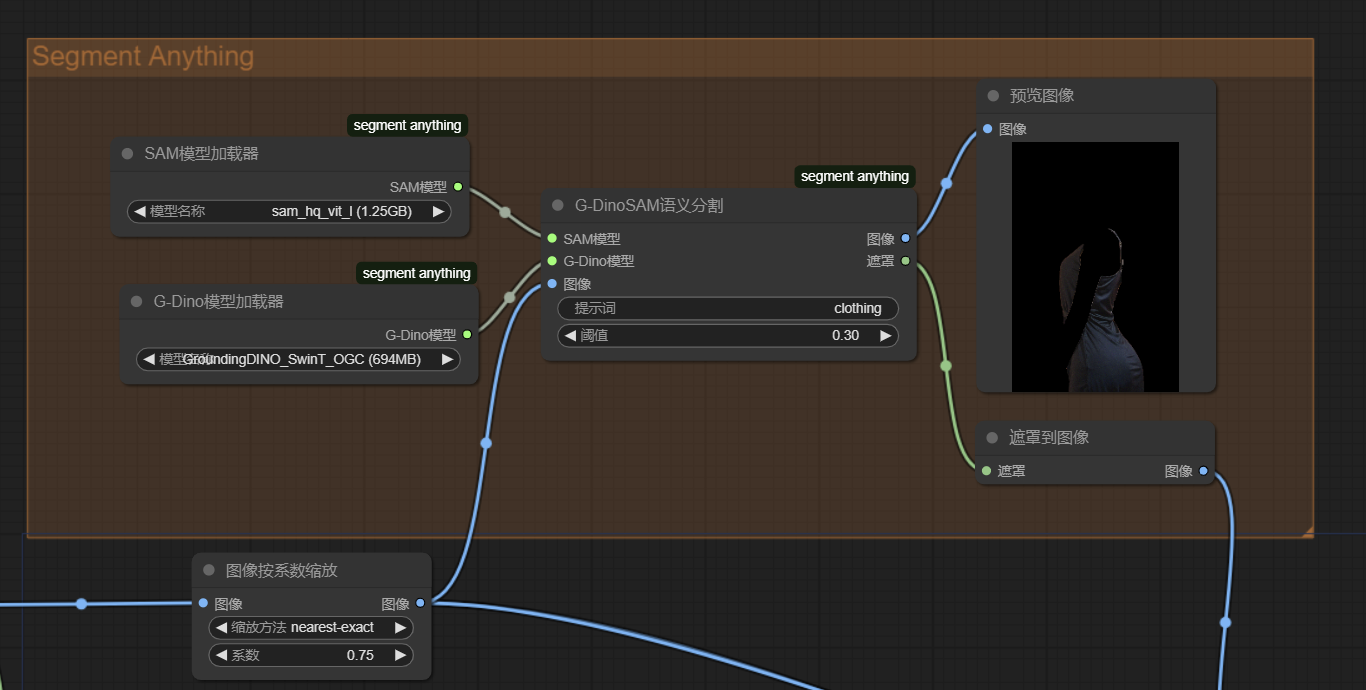
1a) 我们先调用Segment Anything和GroundingDINO模型(通常使用1.25G的SAM模型和938M的G-DINO模型,如果你没有下载过对应模型,第一次运行Segment Anything会自动下载,耗时较长),如图输入图像和提示词(多个提示词用.或&连接,如clothing.hair,如果不想要就空着)
得到对应遮罩。
1b) 然后将该遮罩与你手绘的遮罩通过Masque节点的{合并遮罩}合并(操作为add)。
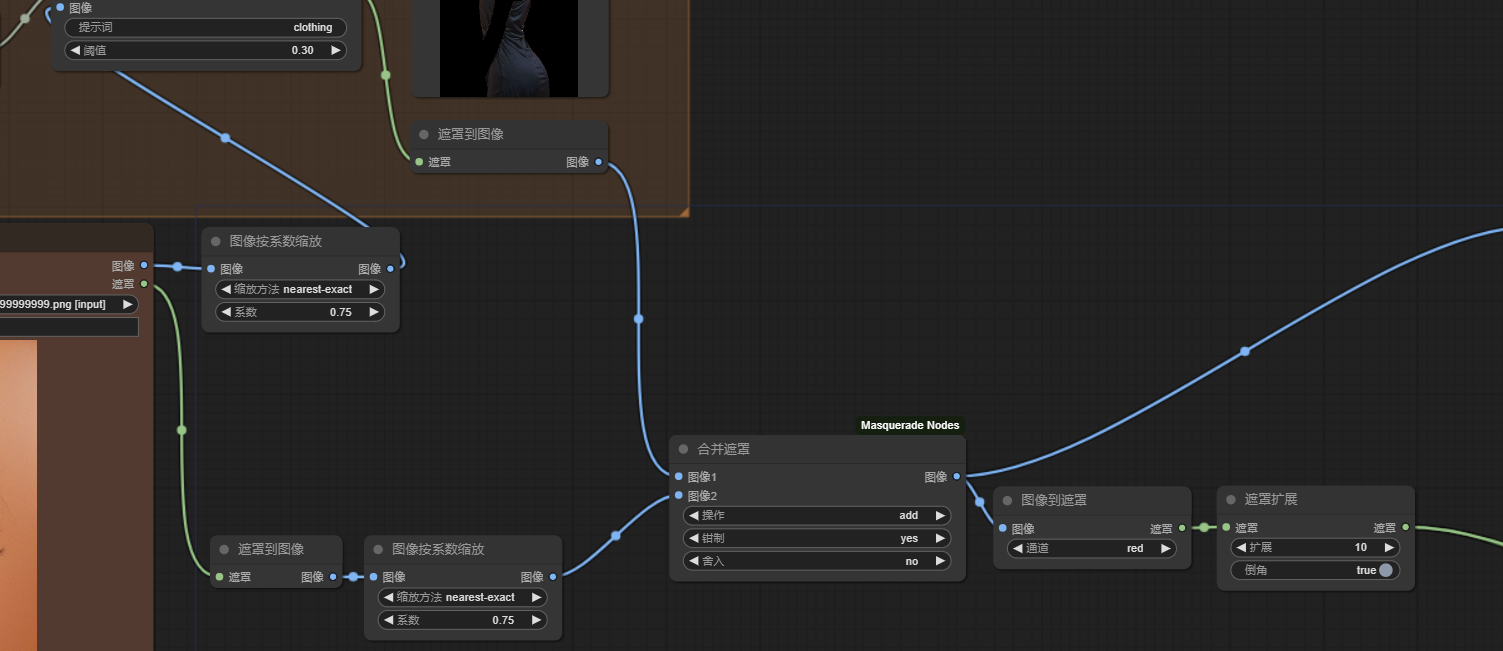
在{加载图像}中你也可以右键选择{在SAM检测中打开}而不是{在遮罩编辑器中打开}以手动绘制遮罩(左键选中需要的区域,右键选中不需要的区域再Detect),但此时默认使用的SAM模型比较低级,因此暂时不建议用这种方式绘制。
值得注意的是,在最开始{加载图像}时会默认生成一个错误的低分辨率遮罩(或许是bug),如果你不想要手绘,请右键{加载图像}选择{在遮罩编辑器中打开}再清除并保存。
(如果你确认不会再手绘遮罩,可以用inspire节点里的{加载图像}替代默认{加载图像},这个不会错误生成遮罩,但其遮罩编辑器里的遮罩会直接覆盖到原图像上,影响后续的节点,因此也不适用于手绘遮罩。)
2. 人体区分
我们已经实现了自动获取遮罩,但如何实现遮罩内不同组分用颜色区分呢?
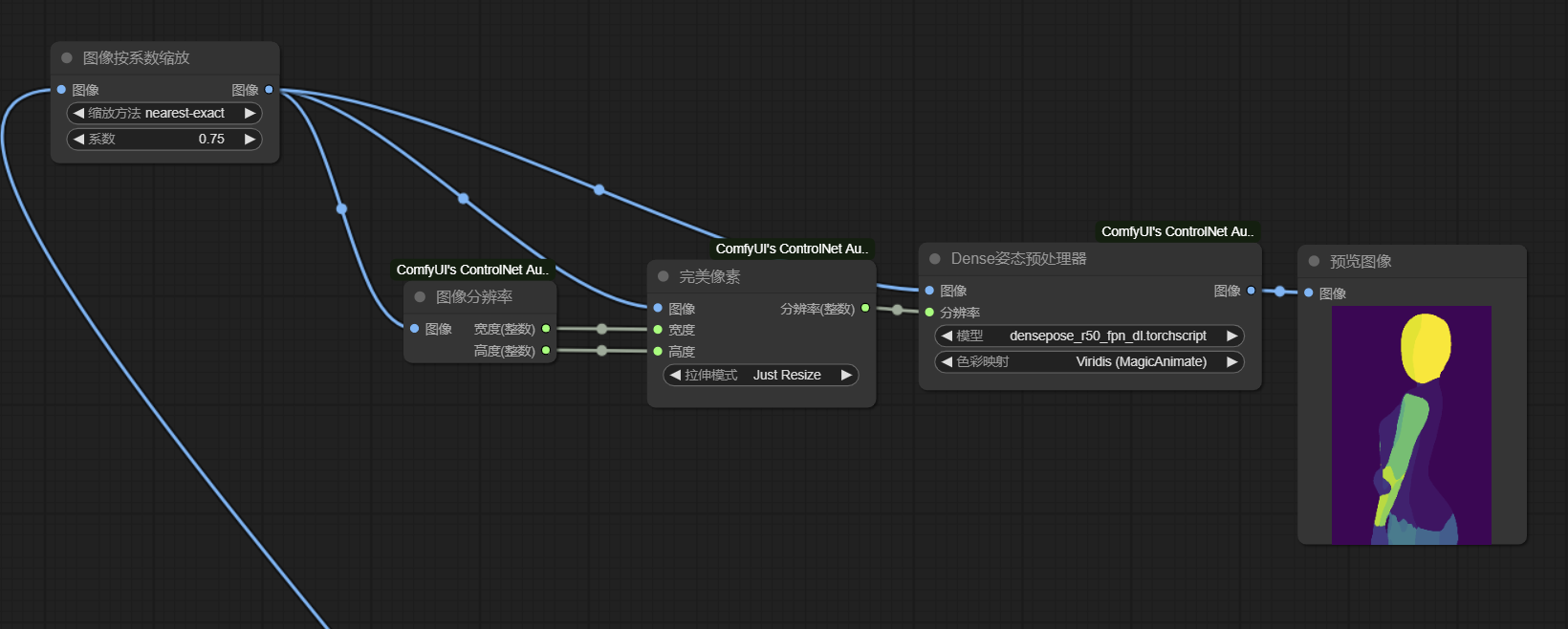
2a) 将缩放后的原图像输入到controlnet的Dense姿态预处理器,如图(右键转换分辨率为输入,使用{完美像素}分辨率)得到DensePose图像,图中色块即模型识别到的人体部位,并且自带颜色区分。
2b) 我们也可以在预处理前将图像先经过Segment Anything识别(如body/girl/woman),以进一步提高DensePose识别人体的准确性。(DensePose预处理会先用yolo模型识别出人体再转化为DensePose图像,因此使用Segment Anything先过滤一遍,这一步在识别一些复杂图像时非常有效)建议跟1a共享模型加载器。
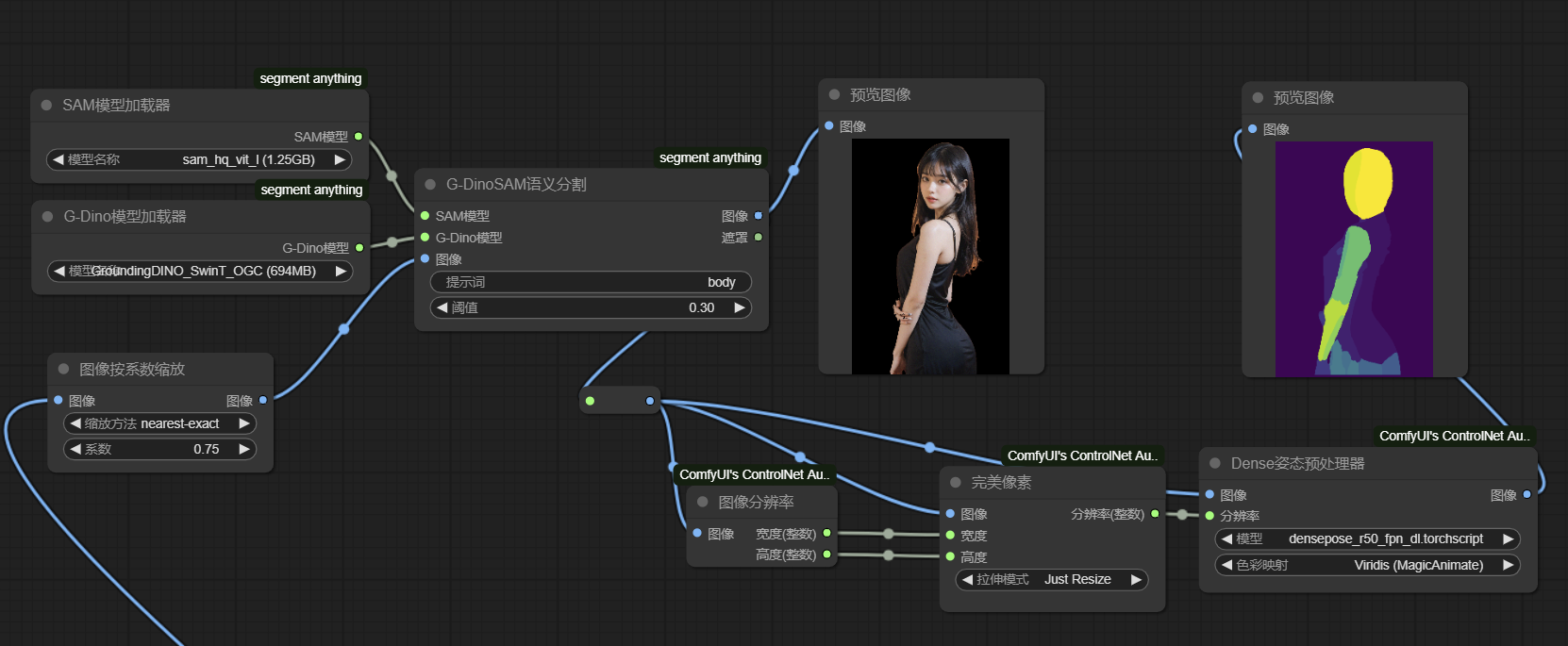
如此,我们得到了较为可靠的人体图像。
值得注意的是,DensePose模型是将人体表面UV图映射到图像上,因此它无法准确识别一些过度扭曲或不自然的人体姿态。
3. 遮罩游戏
在获取遮罩和人体区分之后,我们所要做的事情非常明确了,也就是将遮罩内人体的部分用肤色覆盖。
以下是我处理遮罩的方式,或许存在更优解。
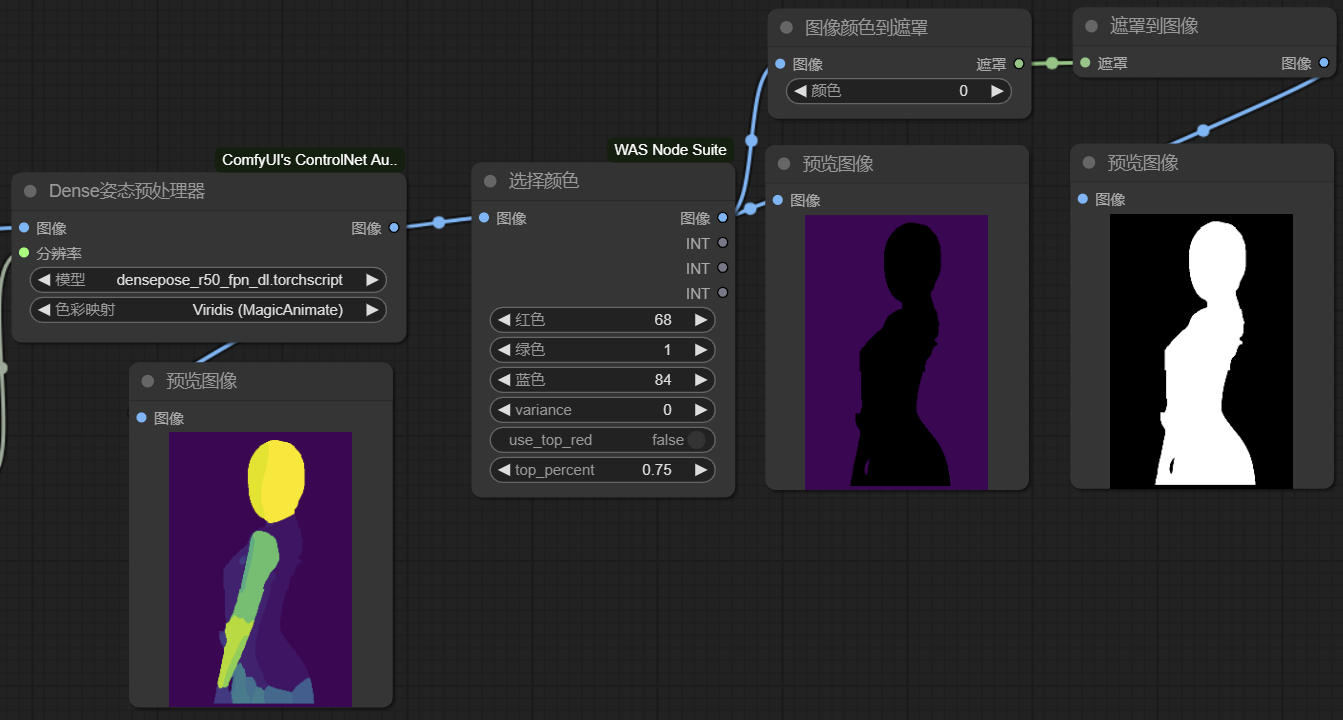
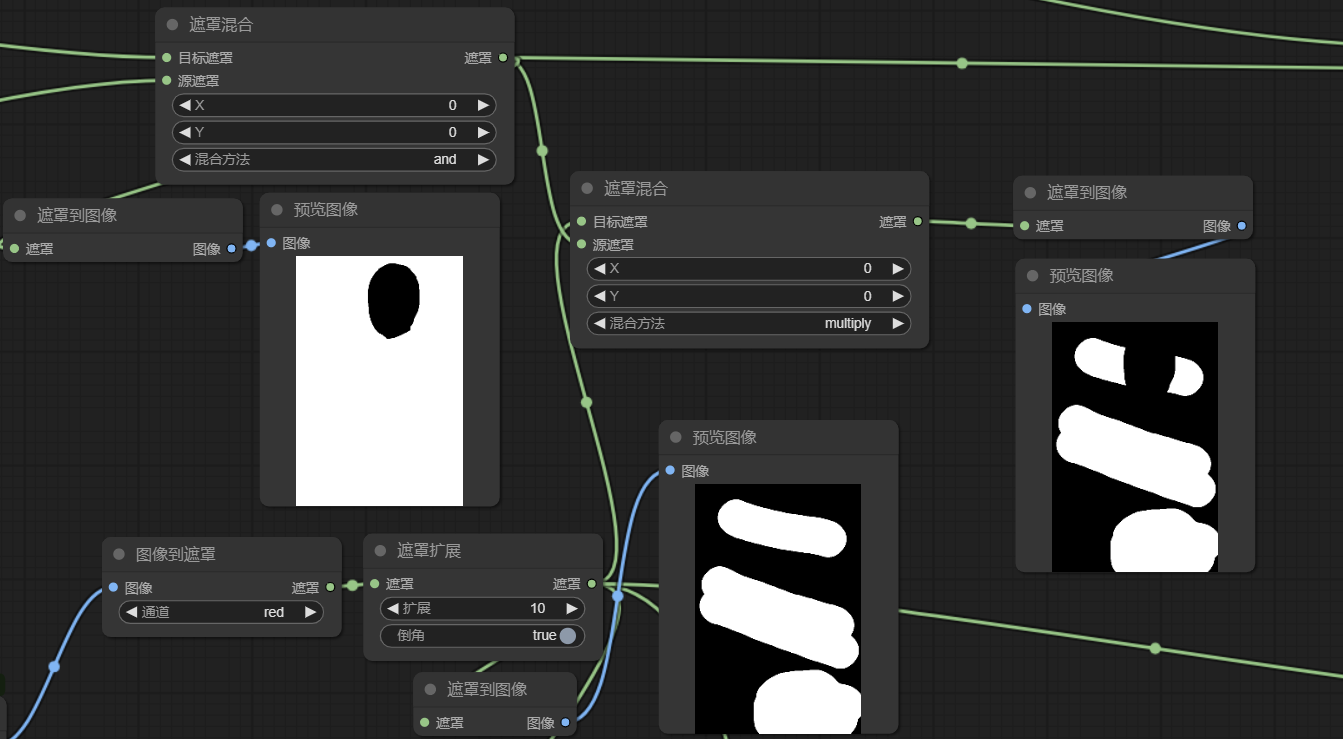
3a) 如图,将DensePose图像经过WAS node的{选择颜色}节点(注意有两个节点都叫做选择颜色,这里用的是Image Select Color),将背景颜色(68, 1, 84, var=0)抠出来,再经过{颜色图像到遮罩},将中间黑色区域转化为遮罩。
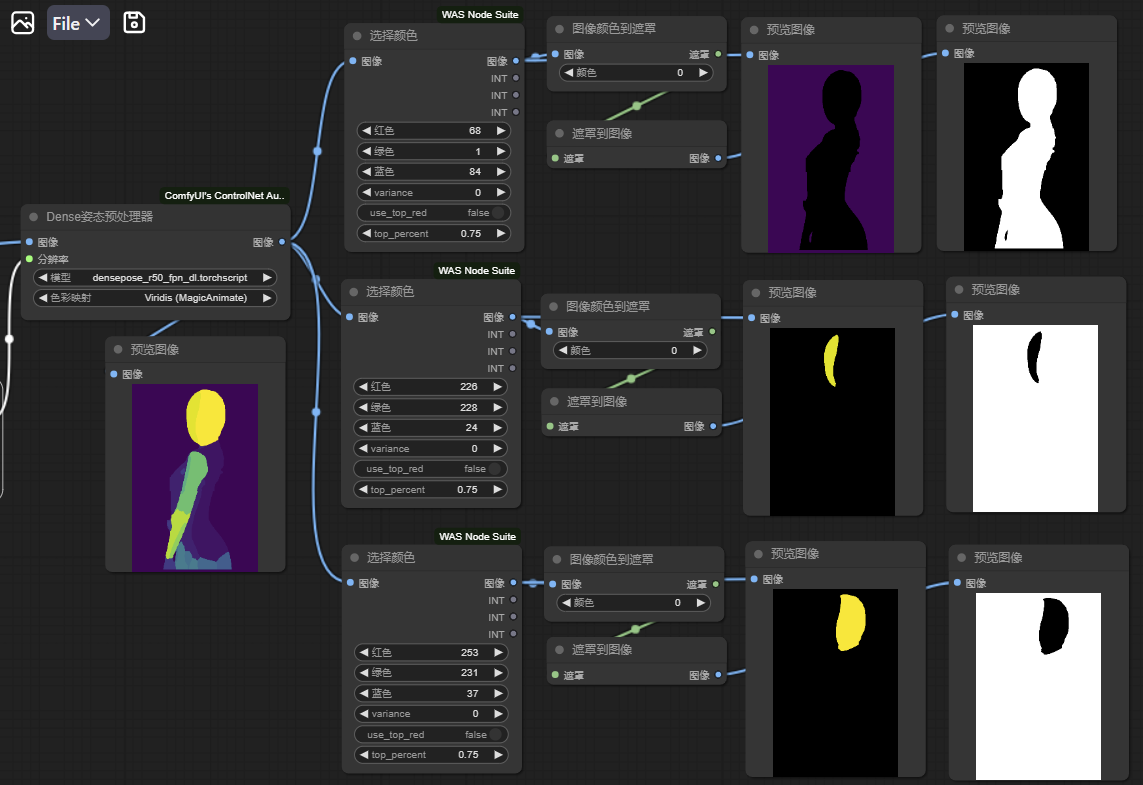
3b) 因为我们不希望遮罩覆盖面部,同样地,我们可以把面部(226, 228, 24, var=0)+(253, 231, 37, var=0)再抠出来
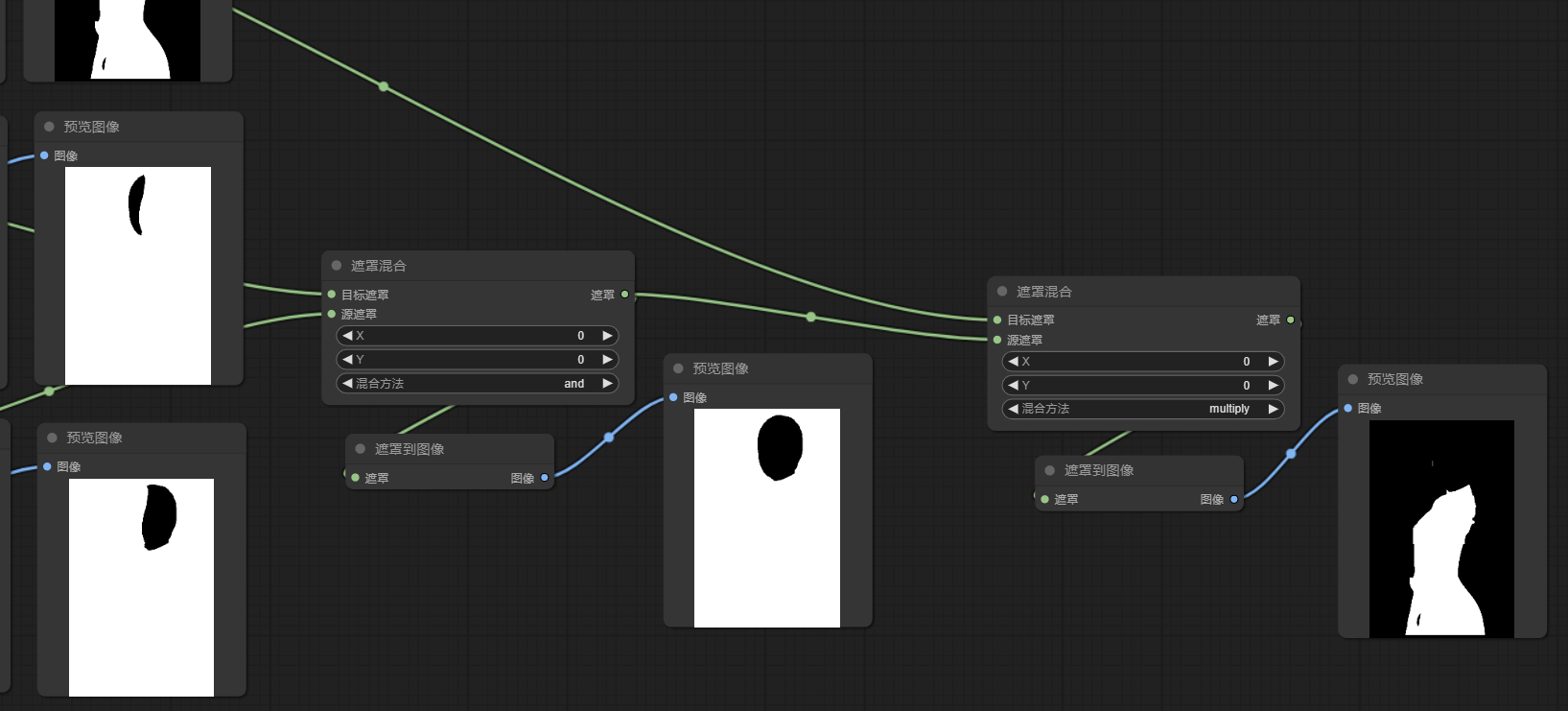
3c) 接下来,就是通过{遮罩混合}剪掉面部——[遮罩A*(遮罩B and 遮罩C)]
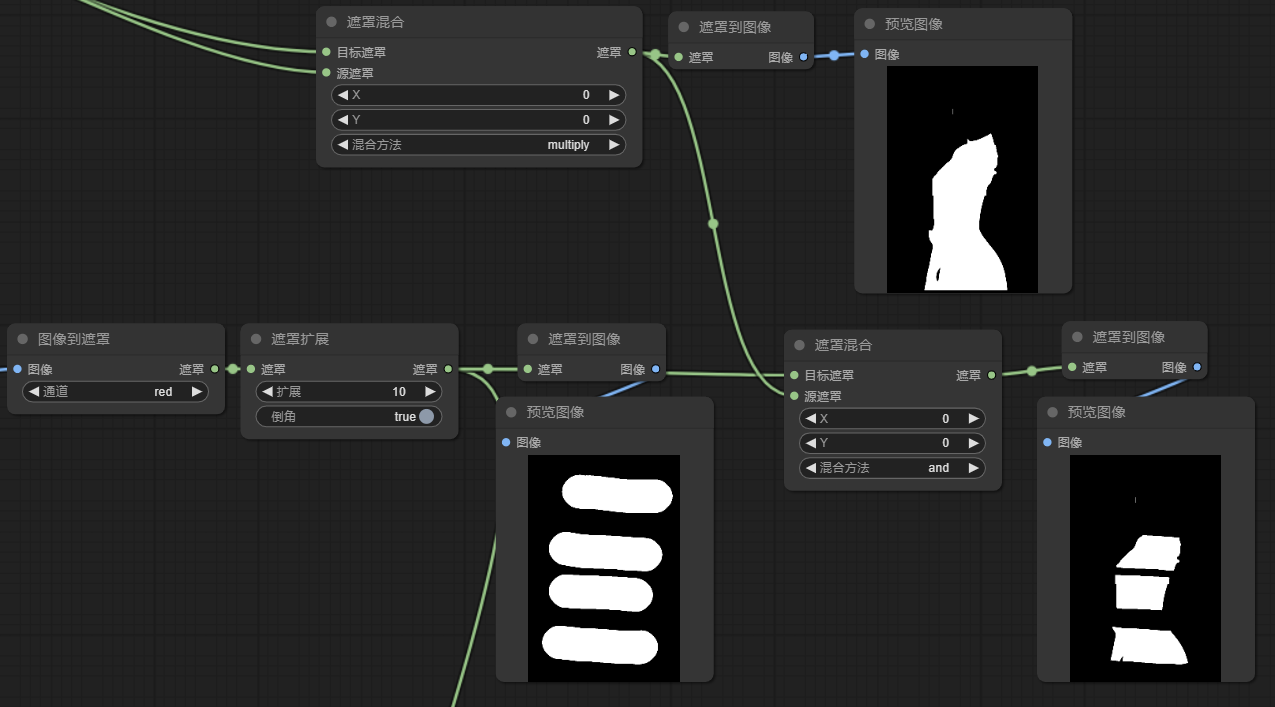
3d) 然后,将第1b步得到的遮罩与第3c步得到人体遮罩用and混合,如图我随手画了4个横条遮罩,最后只保留人体区域的遮罩
3e) 最后,{遮罩混合颜色}为肤色
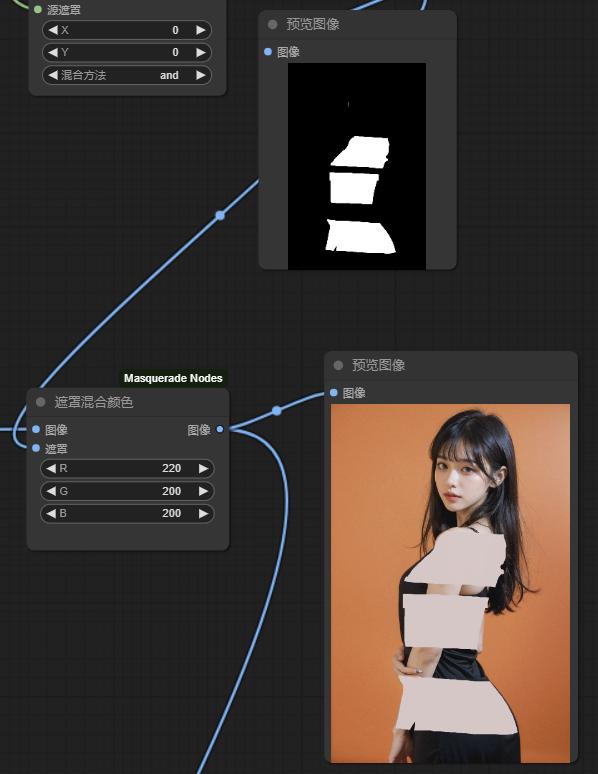
至此,我们终于得到了人体区域的颜色蒙版。
4. 清除
在一开始的问答里,我们知道遮罩内的衣物有可能会导致重绘后肤色异常,那么,对于人体以外的遮罩区域,我们该作何处理呢?
4a) 我们将遮罩与第3c步得到的面部遮罩进行相乘混合,得到非面部区域遮罩。你可能会奇怪为什么这里不是去获得非人体区域遮罩而是非面部区域遮罩,但你先别急。
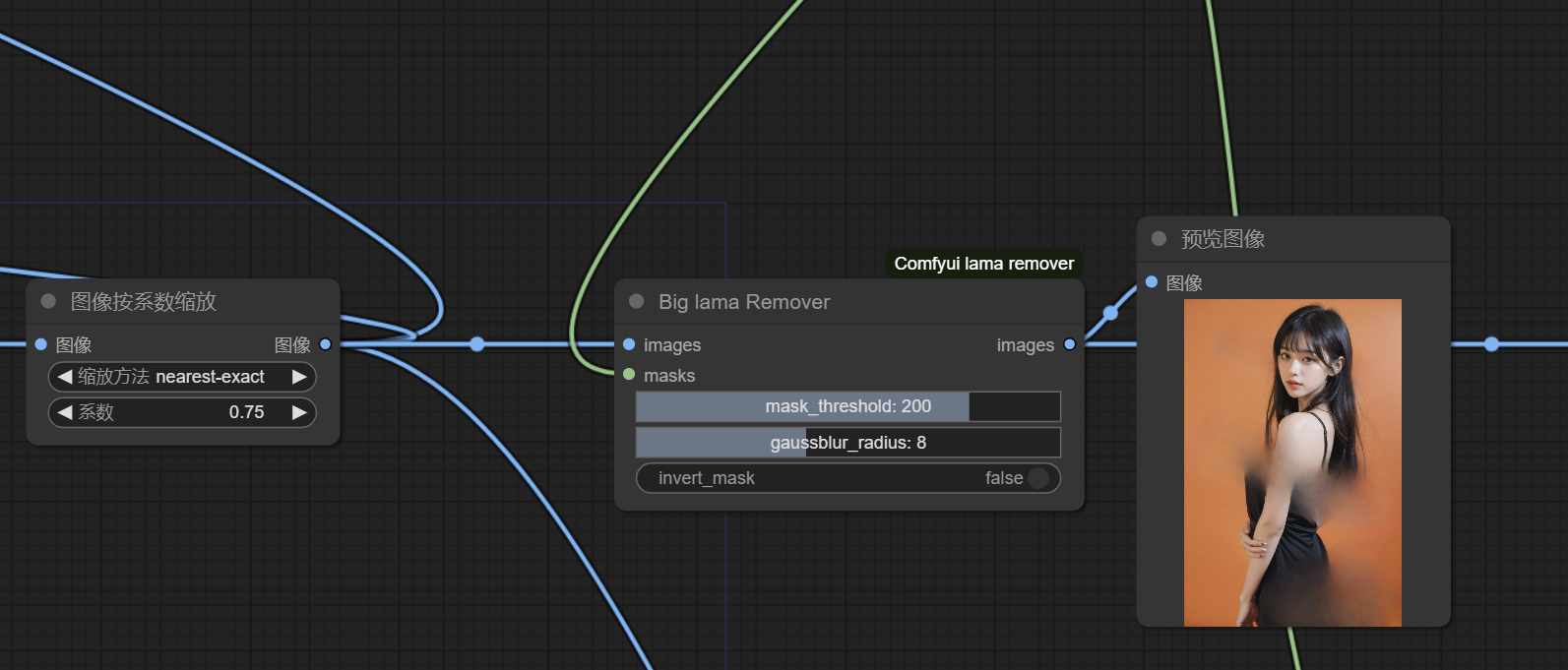
4b) 然后我们直接用Lama Remover将非面部区域遮罩抹掉(如果只抹除非人体区域,跟人体接壤的像素就得不到有效清理)
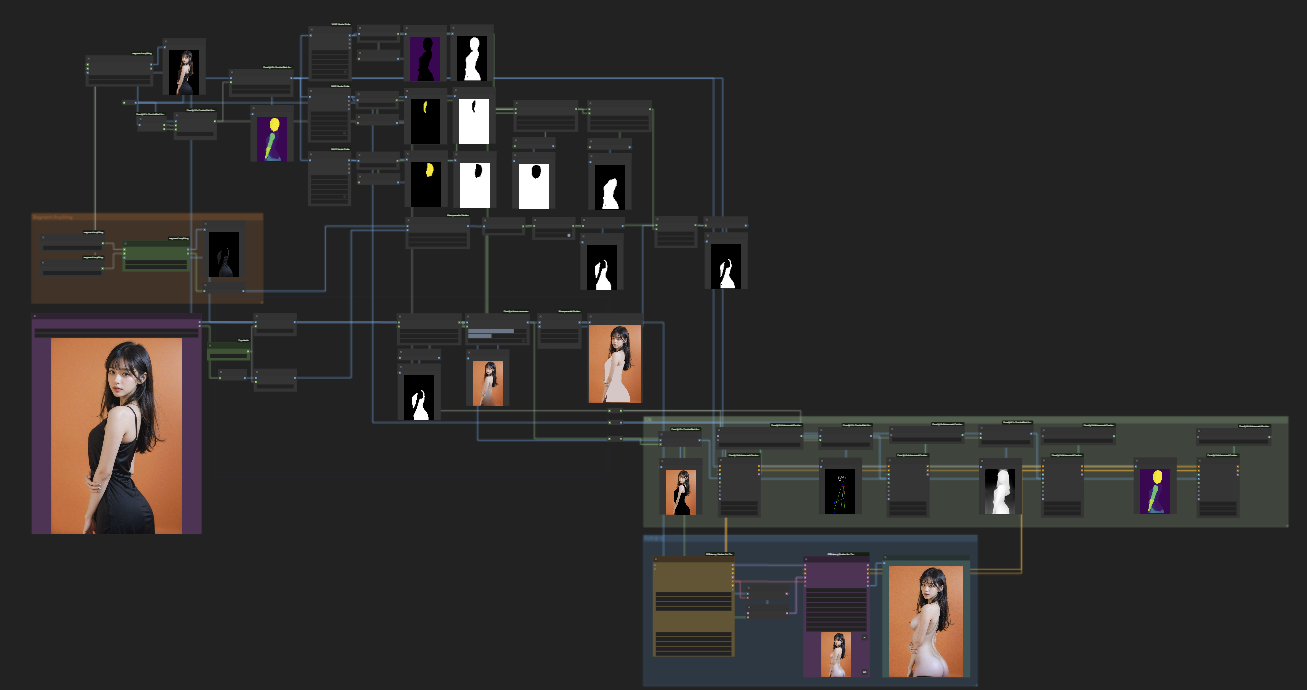
4c) 如图再将输出图像作为第3e步里{遮罩混合颜色}的输入图像,最终我们得到了用于局部重绘的底图,大模型可以非常轻松地在这张图像上重绘出我们想要的去衣效果。

至此,关于自动识别与处理遮罩/蒙版的部分已经结束了。
5. 整合
在整个流程中我们生产了大量的中间图像,想必很多人已经云里雾里了吧,我再简单捋一捋怎么将这些图像接入到基础篇中的核心工作流中。
a. controlnet输入:
inpaint内补预处理器:图像——缩放后的原图像;遮罩——第4a步里得到的非面部区域遮罩
openpose/depth/bae等预处理器:图像——第2b步里segment anything识别到的人体图像;分辨率——第2a步里的完美像素分辨率
b. 局部重绘输入:
VAE编码:图像——第4c步最终图像
设置latent噪波遮罩:遮罩——第4a步里得到的非面部区域遮罩
各位可以自己尝试搭建一下,也可以下载如下示例。
(再提一嘴,{加载图像}时如果不想要手绘请先清除遮罩,或者改用inspire节点里的{加载图像};如果无法翻墙,把DensePose的预处理器换成controlnet aux节点的)
此帖售价 0 SP币,已有 124 人购买若发现会员采用欺骗的方法获取财富,请立刻举报,我们会对会员处以2-N倍的罚金,严重者封掉ID!
如果你有什么新的想法,也欢迎分享。
|







